Getting Started
CompilerGym is a toolkit for applying reinforcement learning to compiler optimization tasks. This document provides a short walkthrough of the key concepts, using the codesize reduction task of a production-grade compiler as an example. It will take about 20 minutes to work through. Lets get started!
Topics covered:
Key Concepts
CompilerGym exposes compiler optimization problems as environments for reinforcement learning. It uses the OpenAI Gym interface to expose the “agent-environment loop” of reinforcement learning:
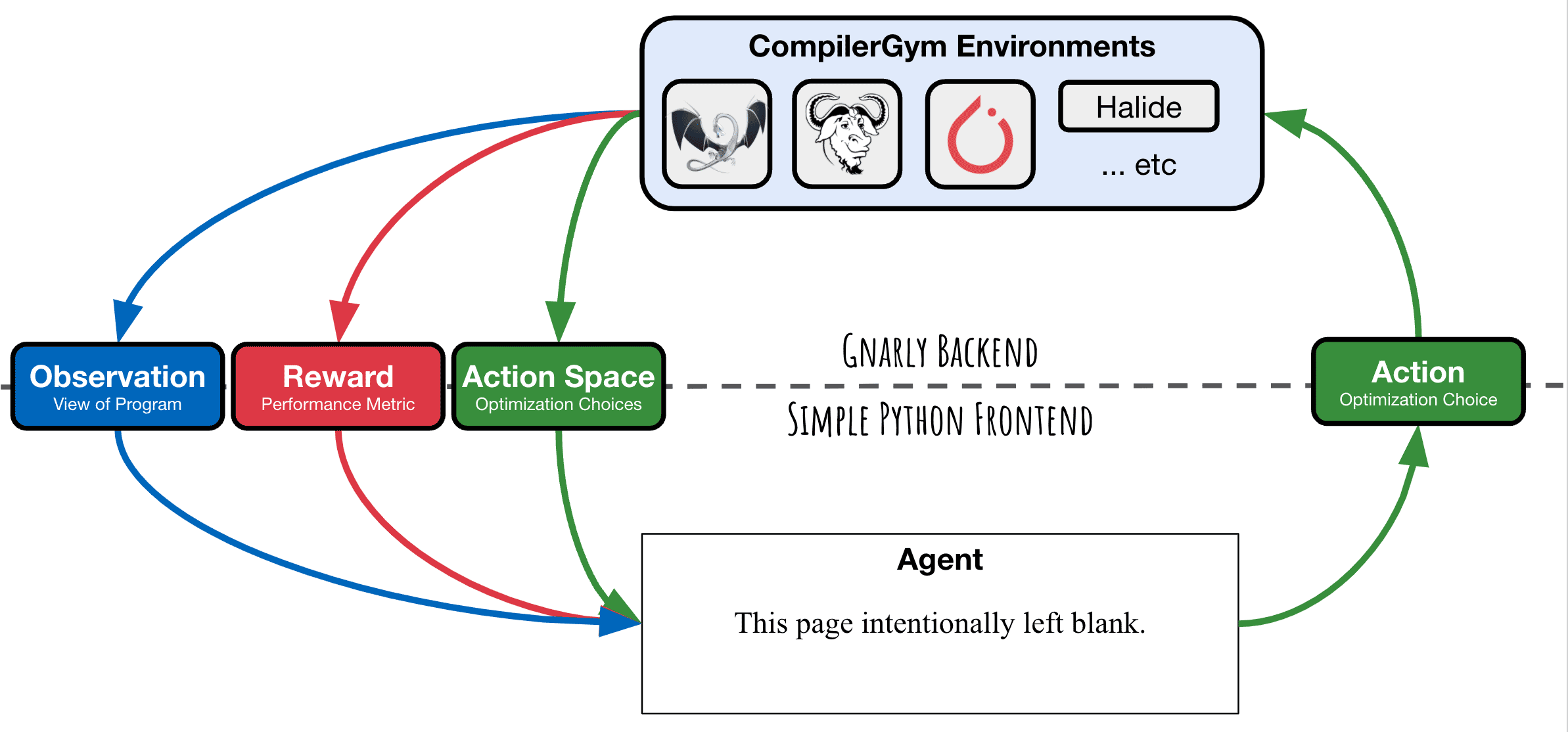
The ingredients for reinforcement learning that CompilerGym provides are:
Environment: a compiler optimization task. For example, optimizing a C++ graph-traversal program for codesize using LLVM. The environment encapsulates an instance of a compiler and a particular program that is being compiled. As an agent interacts with the environment, the state of the program, and the compiler, can change.
Action Space: the actions that may be taken at the current environment state. For example, this could be a set of optimization transformations that the compiler can apply to the program.
Observation: a view of the current environment state. For example, this could be the Intermediate Representation (IR) of the program that is being compiled. The types of observations that are available depend on the compiler.
Reward: a metric indicating the quality of the previous action. For example, for a codesize optimization task this could be the change to the number of instructions of the previous action.
A single instance of this “agent-environment loop” represents the compilation of a particular program. The goal is to develop an agent that maximises the cumulative reward from these environments so as to produce the best programs.
Install the latest CompilerGym release using:
pip install -U compiler_gym
See INSTALL.md for alternative installation methods.
Using CompilerGym
Begin by firing up a python interpreter:
python
To start with we import the gym module and the CompilerGym environments:
>>> import gym
>>> import compiler_gym
Importing compiler_gym automatically registers the compiler environments.
We can see what environments are available using:
>>> compiler_gym.COMPILER_GYM_ENVS
['llvm-v0', 'llvm-ic-v0', 'llvm-autophase-ic-v0', 'llvm-ir-ic-v0']
Selecting an environment
CompilerGym environments are named using one of the following formats:
<compiler>-<observation>-<reward>-<version><compiler>-<reward>-<version><compiler>-<version>
Where <compiler> identifiers the compiler optimization task,
<observation> is the default type of observations that are provided,
and <reward> is the reward signal.
Note
A key concept is that CompilerGym environments enables lazy evaluation
of observations and reward signals. This increases computational efficiency
sampling for scenarios in which you do not need to compute a reward or
observation for every step. If an environment omits a <observation>
or <reward> tag, this means that no observation or reward is
provided by default. See compiler_gym.views for
further details.
For this tutorial, we will use the following environment:
Compiler: LLVM.
Observation Type: Autophase.
Reward Signal: IR Instruction count relative to -Oz.
Create an instance of this environment using:
>>> env = gym.make("llvm-autophase-ic-v0")
Note
The first time you run gym.make() you may see a logging message
“Downloading <url> …” followed by a delay of 1-2 minutes. This is
CompilerGym downloading large environment-specific dependencies that are not
shipped by default to keep the size of the package down. This is a one-off
download that occurs only the first time the environment is used. Other
operations that require one-off downloads include installing datasets
(described below).
The compiler environment
If you have experience using OpenAI Gym, the
CompilerGym environments will be familiar. If not, you can call help()
on any function, object, or method to query the documentation:
>>> help(env.step)
The action space is described by
env.action_space.
The LLVM Action Space is discrete:
>>> env.action_space.dtype
dtype('int64')
>>> env.action_space.n
138
The observation space is described by
env.observation_space.
The Autophase observation space is a 56-dimension
vector of integers:
>>> env.observation_space.shape
(56,)
>>> env.observation_space.dtype
dtype('int64')
The upper and lower bounds of the reward signal are described by
env.reward_range:
>>> env.reward_range
(0.0, inf)
As with other Gym environments, reset() must be called before a CompilerGym
environment may be used.
>>> env.reset()
array([ 0, 4, 54, 39, 12, 46, 23, 6, 12, 31, 2, 4, 0,
81, 4, 77, 13, 15, 108, 106, 75, 51, 71, 46, 15, 0,
9, 46, 0, 13, 72, 51, 77, 81, 39, 31, 0, 163, 2,
0, 4, 6, 13, 1, 0, 73, 8, 1, 0, 15, 85, 638,
402, 16, 10, 298])
The numpy array that is returned by reset() is the initial observation of the program
state. This value, along with the entire dynamics of the environment, depends on
the particular program that is being compiled. In CompilerGym these programs are
called benchmarks. You can see which benchmark is currently being used by an
environment using env.benchmark:
>>> env.benchmark
benchmark://cbench-v1/qsort
If we want to compile a different program, we can pass the name of a benchmark
to env.reset():
>>> env.reset(benchmark="benchmark://npb-v0/50")
array([ 0, 0, 26, 25, 1, 26, 10, 1, 8, 10, 0,
0, 0, 37, 0, 36, 0, 2, 46, 175, 1664, 1212,
263, 26, 193, 0, 59, 6, 0, 3, 32, 0, 36,
10, 1058, 10, 0, 840, 0, 0, 0, 1, 416, 0,
0, 148, 60, 0, 0, 0, 37, 3008, 2062, 9, 0,
1262])
We provide over a million benchmarks for the LLVM environments that can be used for training agents and evaluating the
generalization of strategies across unseen programs. Benchmarks are grouped into
datasets , which are managed using env.datasets. You may also provide your own programs to use
as benchmarks, see env.make_benchmark() for details.
Interacting with the environment
Once an environment has been initialized, you interact with it in the same way
that you would with any other OpenAI Gym
environment. env.render() prints
the Intermediate Representation (IR) of the program in the current state:
>>> env.render()
; ModuleID = 'benchmark://npb-v0/83'
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-pc-linux-gnu"
...
env.step() runs an action:
>>> observation, reward, done, info = env.step(0)
This returns four values: a new observation, a reward, a boolean value indicating whether the episode has ended, and a dictionary of additional information:
>>> observation
array([ 0, 0, 26, 25, 1, 26, 10, 1, 8, 10, 0,
0, 0, 37, 0, 36, 0, 2, 46, 175, 1664, 1212,
263, 26, 193, 0, 59, 6, 0, 3, 32, 0, 36,
10, 1058, 10, 0, 840, 0, 0, 0, 1, 416, 0,
0, 148, 60, 0, 0, 0, 37, 3008, 2062, 9, 0,
1262])
>>> reward
0.3151595744680851
>>> done
False
>>> info
{'action_had_no_effect': True, 'new_action_space': False}
For this environment, reward represents the reduction in code size of the
previous action, scaled to the total codesize reduction achieved with LLVM’s
-Oz optimizations enabled. A cumulative reward greater than one means
that the sequence of optimizations performed yields better results than LLVM’s
default optimizations. Let’s run 100 random actions and see how close we can
get:
>>> env.reset(benchmark="benchmark://npb-v0/50")
>>> episode_reward = 0
>>> for i in range(1, 101):
... observation, reward, done, info = env.step(env.action_space.sample())
... if done:
... break
... episode_reward += reward
... print(f"Step {i}, quality={episode_reward:.3%}")
...
Step 1, quality=44.299%
Step 2, quality=44.299%
Step 3, quality=44.299%
Step 4, quality=44.299%
Step 5, quality=44.299%
Step 6, quality=54.671%
Step 7, quality=54.671%
Step 8, quality=54.608%
Step 9, quality=54.608%
Step 10, quality=54.608%
Step 11, quality=54.608%
Step 12, quality=54.766%
Step 13, quality=54.766%
Step 14, quality=53.650%
Step 15, quality=53.650%
...
Step 97, quality=88.104%
Step 98, quality=88.104%
Step 99, quality=88.104%
Step 100, quality=88.104%
Not bad, but clearly there is room for improvement! Because at each step we are taking random actions, your results will differ with every run. Try running it again. Was the result better or worse? Of course, there may be better ways of selecting actions than choosing randomly, but for the purpose of this tutorial we will leave that as an exercise for the reader :)
Before we finish, lets use
env.commandline()
to produce an LLVM opt command line invocation that is equivalent to
the sequence of actions we just run:
>>> env.commandline()
'opt -consthoist -sancov -inferattrs ... -place-safepoints input.bc -o output.bc'
We can also save the program in its current state for future reference:
>>> env.write_bitcode("~/program.bc")
Once we are finished, we must close the environment to end the compiler session:
>>> env.close()
And finally we are done with our python session:
>>> exit()
Note
Internally, CompilerGym environments may launch subprocesses and use
temporary files to communicate between the environment and the underlying
compiler (see compiler_gym.service for
details). This means it is important to call env.close() after use to free up resources and
prevent orphan subprocesses or files. We recommend using the with
statement pattern for creating environments:
>>> with gym.make("llvm-autophase-ic-v0") as env:
... env.reset()
... # use env how you like
This removes the need to call env.close() yourself.
Using the command line tools
CompilerGym includes a set of useful command line tools. Each of the steps above could be replicated from the command line.
For example, compiler_gym.bin.service can be used to list the available
environments:
$ python -m compiler_gym.bin.service --ls_env
llvm-v0
...
And to describe the capabilities of each environment:
$ python -m compiler_gym.bin.service --env=llvm-v0
Datasets
--------
+----------------------------+--------------------------+------------------------------+
| Dataset | Num. Benchmarks [#f1]_ | Description |
+============================+==========================+==============================+
| benchmark://anghabench-v0 | 1,042,976 | Compile-only C/C++ functions |
+----------------------------+--------------------------+------------------------------+
| benchmark://blas-v0 | 300 | Basic linear algebra kernels |
+----------------------------+--------------------------+------------------------------+
...
Observation Spaces
------------------
+--------------------------+----------------------------------------------+
| Observation space | Shape |
+==========================+==============================================+
| Autophase | `Box(0, 9223372036854775807, (56,), int64)` |
+--------------------------+----------------------------------------------+
| AutophaseDict | `Dict(ArgsPhi:int<0,inf>, BB03Phi:int<0,...` |
+--------------------------+----------------------------------------------+
| BitcodeFile | `str_list<>[0,4096.0])` |
+--------------------------+----------------------------------------------+
...
The compiler_gym.bin.manual_env module provides an interactive text user
interface for CompilerGym environments:
$ python -m compiler_gym.bin.manual_env --env=llvm-v0
Initialized environment in 144.3ms
Welcome to the CompilerGym Shell!
---------------------------------
Type help or ? for more information.
The 'tutorial' command will give a step by step guide.
compiler_gym:cbench-v1/qsort> help
Documented commands (type help <topic>):
========================================
action help list_rewards set_default_observation
back hill_climb observation set_default_reward
breakpoint list_actions require_dataset simplify_stack
commandline list_benchmarks reset stack
exit list_datasets reward try_all_actions
greedy list_observations set_benchmark tutorial
Finally, the compiler_gym.bin.random_search module provides a simple but
efficient implementation for randomly searching the optimization space:
$ python -m compiler_gym.bin.random_search --env=llvm-autophase-ic-v0 --benchmark=npb-v0/50 --runtime=10
Started 24 worker threads for using reward IrInstructionCountOz.
Writing logs to /home/user/logs/compiler_gym/random/npb-v0/50/2021-04-21T16:42:41.038447
=== Running for 10 seconds ===
Runtime: 10 seconds. Num steps: 21,563 (2,105 / sec). Num episodes: 141 (13 / sec). Num restarts: 0.
Best reward: 1.0228 (141 passes, found after 4 seconds)
Ending worker threads ... done
Replaying actions from best solution found:
Step [001 / 141]: reward=0.0000 episode=0.0000 action=-hotcoldsplit
Step [002 / 141]: reward=0.0000 episode=0.0000 action=-scalarizer
Step [003 / 141]: reward=0.0000 episode=0.0000 action=-redundant-dbg-inst-elim
...
Step [139 / 141]: reward=0.0000 episode=1.0218 action=-barrier
Step [140 / 141]: reward=0.0000 episode=1.0218 action=-sink
Step [141 / 141]: reward=0.0010 episode=1.0228 action=-loop-simplifycfg
+---------------------------+-------+-------+---------+
| | -O0 | -Oz | final |
+===========================+=======+=======+=========+
| IR instruction count | 3008 | 948 | 901 |
+---------------------------+-------+-------+---------+
| Object .text size (bytes) | 13047 | 10991 | 10399 |
+---------------------------+-------+-------+---------+
To beat the compiler by 2.28% after 10 seconds of random trials is not bad going!
Next Steps
Now that you have got to grips with the compiler environment, take a browse through the examples directory for pytorch integration, agent implementations, etc. Then check out the leaderboards to see what the best performing algorithms are, and the documentation for details of the APIs and environments. We love feedback, bug reports, and feature requests - please file an issue!